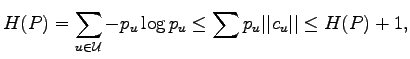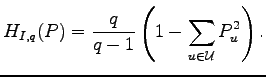|
Allgemeine Theorie des Informationstransfer und Kombinatorik
Erstantrag
Apart from the funding granted by the DFG the project also received financial strengthening by the
much more broadly applied 3 year research project ``General Theory of Information Transfer and
Combinatorics'', led by us, at the Zentrum für interdisziplinäre Forschung (ZiF) with the
intensive research year 1.10.02-31.8.03.
Within this scope it was in particular possible to relieve the DFG project financially, so that its
period of time extended itself by about 2 1/2 years.
The interaction with about 100 fellows in two weekly seminars of four hours each led to fundamental
ideas and publications, which for a large part, but not exclusively, appeared in the book
``General Theory of Information Transfer and Combinatorics'', Lecture Notes in Computer Science,
Springer Verlag, Vol. 4123, 2006 and appear in a Special Issue of Discrete Applied Mathematics.
While discussing contributions to the areas A.1-A.4 and B.1-B.4 we indicate also connections to the
questions (1)-(42),
which are formulated in the original project (Erstantrag).
A.1
We start with one of the key results.
Transmission, identification
and common randomness, via a wiretap channel with secure feedback
are studied in the work [P6]. Recall that wiretap channels were introduced by
A. D. Wyner [28] and were generalized by I. Csiszár and J. Körner [15].
Its identification capacity was determined by R. Ahlswede
and Z. Zhang in [9]. In the article here secure feedback is introduced to wiretap
channels. Here by secure feedback we mean that the feedback
is noiseless and that the wiretaper has no knowledge about the content
of the feedback except via his own output. Lower and upper
bounds to the transmission capacity are derived. The two bounds are
shown to coincide for two families of degraded wiretap channels,
including Wyner's original version of the wiretap channel. The identification
and common randomness capacities for the channels are completely
determined. Also here again identification capacity is much bigger than common
randomness capacity, because the common randomness used for the (secured) identification
needs not to be secured! (ad (1))
In the work of Z. Zhang [29] the scheme of encrypting the data 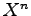 by using the key set
by using the key set 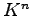 and
function
and
function
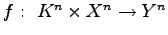 is considered. Under given distribution of
the value of
the conditional entropy
is considered. Under given distribution of
the value of
the conditional entropy
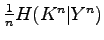 which is offered as the measure of the secrecy of the system is investigated.
In several natural cases an expression for this measure (which is called `key equivocation rate')
in terms of sizes of alphabets and distributions of
is derived.
The secrecy system with ALIB encipherers was investigated in [6] and is adapted in [P5] to
satisfy the model of identification via channels. The smallest key rate of the ALIB encipherers
needed for the requirement of security is analyzed. (ad (1))
which is offered as the measure of the secrecy of the system is investigated.
In several natural cases an expression for this measure (which is called `key equivocation rate')
in terms of sizes of alphabets and distributions of
is derived.
The secrecy system with ALIB encipherers was investigated in [6] and is adapted in [P5] to
satisfy the model of identification via channels. The smallest key rate of the ALIB encipherers
needed for the requirement of security is analyzed. (ad (1))
In [P4] we discuss the watermarking identification introduced by
Y. Steinberg and N. Merhav. It is assumed in their model
that the attacker uses a single channel known by both, information
hider and decoder, and the decoder either completely knows the
covertext or knows nothing about it. Thus Steinberg and Merhav asked for more
robust watermarking systems i.e., the attacker can choose an unknown
attack channel from a family of channels, and more general watermarking
models i.e., the decoder has side information about the covertext.
To answer their questions we present a direct coding theorem of
identification watermarking codes for compound channels with the
presence of side information at the decoder.
To construct the codes we establish coding theorems for the related common
randomness.(ad(1))
Shannon (1948) has shown that a source
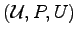 with output
with output
 satisfying Prob
satisfying Prob 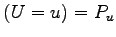 , can be encoded in a prefix code
, can be encoded in a prefix code
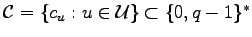 such that for the entropy
such that for the entropy
where  is the length of
is the length of  .
In [P2] a prefix code
.
In [P2] a prefix code 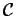 is used for another purpose, namely noiseless
identification, that is every user who wants to know
whether a
is used for another purpose, namely noiseless
identification, that is every user who wants to know
whether a 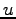
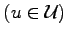 of his interest is the actual source output or
not can consider the RV
of his interest is the actual source output or
not can consider the RV 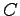 with
with
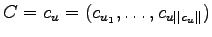 and check whether
and check whether
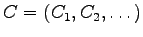 coincides with
in the first,
second etc. letter and stop when the first different letter occurs
or when
coincides with
in the first,
second etc. letter and stop when the first different letter occurs
or when 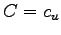 .
Let
.
Let
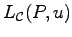 be the expected number of checkings, if
code
is used.
Discovered is an identification entropy, namely the function
be the expected number of checkings, if
code
is used.
Discovered is an identification entropy, namely the function
We prove that
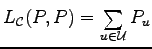
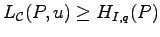 and thus also that
and thus also that
and related upper bounds, which demonstrate the operational
significance of identification entropy in noiseless
source coding similar as Boltzmann/Shannon entropy does in noiseless
data compression.
It has been brought to our attention that in Statistical Physics an entropy
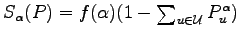 has been used in
Equilibrium Theory for more pathological cases, where Boltzmann's
has been used in
Equilibrium Theory for more pathological cases, where Boltzmann's 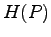 fails.
Attempts to find operational justifications in Coding Theory have failed.
It is important here that
fails.
Attempts to find operational justifications in Coding Theory have failed.
It is important here that
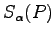 (in particular also
(in particular also 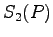 ),
which is to be compared with
),
which is to be compared with
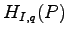 ,
does not have the parameter
,
does not have the parameter 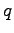 , the size of the alphabet for coding.
The factor
, the size of the alphabet for coding.
The factor
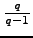 equals the sum of the geometric series
equals the sum of the geometric series
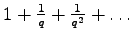 ,
which also has an operational meaning for identification as explained in [P3].
also has a
in its formula, it is the basis of the
,
which also has an operational meaning for identification as explained in [P3].
also has a
in its formula, it is the basis of the  - function for which Shannon's result
holds!
We emphasize, that storing the outcome of a source as a leaf in a prefix code constitutes a
data structure which is very practical. Let for instance the
specify the person
out of a group
- function for which Shannon's result
holds!
We emphasize, that storing the outcome of a source as a leaf in a prefix code constitutes a
data structure which is very practical. Let for instance the
specify the person
out of a group 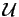 of persons, who has to
do a certain service. Then every person traces along the tree to find
out whether he/she has to go on service. We know that its expected reading time is always
of persons, who has to
do a certain service. Then every person traces along the tree to find
out whether he/she has to go on service. We know that its expected reading time is always 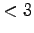 no matter how big
no matter how big
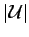 is. This goes so fast, because the persons care in this model only about themselves.
If they don't have service, then they don't care in this model who has.
Finding out the latter takes time
is. This goes so fast, because the persons care in this model only about themselves.
If they don't have service, then they don't care in this model who has.
Finding out the latter takes time 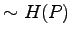 and goes to infinity as
does. Notice that
and goes to infinity as
does. Notice that
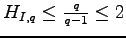 .
Recently we learned that J. Havrda and F. Charvát ([21]) introduced already in 1967 an entropy,
which for
.
Recently we learned that J. Havrda and F. Charvát ([21]) introduced already in 1967 an entropy,
which for 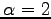 coincides with identification entropy for
coincides with identification entropy for 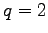 . There are no applications
and cases
. There are no applications
and cases 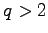 are not covered. (ad (3))
are not covered. (ad (3))
C. Heup introduced in his dissertation [P8] a related L-identification entropy.
(ad (4) and (5)).
Codes with identifiable parent property were introduced by H.D.L. Hollmann,
J.H. van Lint, J.P. Lennartz, and L.M.G.M. Tolhuizen [22] for protection
of copyright. Let 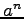 and
and 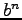 be two words of the same length
from a finite alphabet. Then a descendant of them is a word of the same length
such that each component coincides with the corresponding component of either
or
, who are called its parents. Identifiable parent property
of a code means that one can discover at least one parent from the descendant
of any pair of codewords in the code. R. Ahlswede and N. Cai observed in [P7]
its relation with coding for multiple access channels. Its probabilistic
version is coding for a multiple access channel such that two senders have
the same codebook and the receiver has to decode the message at least from one
of the two senders. This leads them to a coding problem for the multiple
access channel, where the two senders are allowed to use different
codebooks and again the receiver only needs to decode the message
sent by anyone of the two senders. The capacity region is determined
and the result shows that an optimal strategy for the receiver is to always
decode the message from a fixed sender. The result has a simple consequence
for the interference channel with one deterministic component which seems to be
new.
be two words of the same length
from a finite alphabet. Then a descendant of them is a word of the same length
such that each component coincides with the corresponding component of either
or
, who are called its parents. Identifiable parent property
of a code means that one can discover at least one parent from the descendant
of any pair of codewords in the code. R. Ahlswede and N. Cai observed in [P7]
its relation with coding for multiple access channels. Its probabilistic
version is coding for a multiple access channel such that two senders have
the same codebook and the receiver has to decode the message at least from one
of the two senders. This leads them to a coding problem for the multiple
access channel, where the two senders are allowed to use different
codebooks and again the receiver only needs to decode the message
sent by anyone of the two senders. The capacity region is determined
and the result shows that an optimal strategy for the receiver is to always
decode the message from a fixed sender. The result has a simple consequence
for the interference channel with one deterministic component which seems to be
new.
In [P9] and [P10] we studied a special type of
-ary unidirectional
and asymmetric error correcting codes.
In these codes the number of errors can be very big, however the
magnitude of error (referred to as level) is bounded.
These codes are of practical use in many real communication systems.
A class of optimal
-ary codes correcting all unidirectional errors
of a given level has been constructed.
The model considered in [P11] has applications when storing
information on digital media. The corresponding 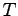 -shift synchronization
codes of a fixed block length generalize the cover free codes. We construct
a family of
-shift synchronization codes, which are asymptotically
optimal for an infinite number of values of
.
-shift synchronization
codes of a fixed block length generalize the cover free codes. We construct
a family of
-shift synchronization codes, which are asymptotically
optimal for an infinite number of values of
.
A.2
The results of L. Bäumer's phd thesis were published in [P12].
A.3 and A.4
This work received financial support in part also from DFG-AH 46/2. We refer to our final report (Abschlussbericht)
there. We just point out here two highlights, [P20] and [P21], relating to the fundamental question of finding
quantum versions of classical methods.
The first paper [P20] is on classical
quantum multiple access channels. The coding and weak converse theorem for
classical multiple access channels of [1] was extended to classical
quantum multiple access channels in [27]. But the extension of the
strong converse theorem has been open for several years. One reason, but likely not the only one, for it is
that so far an analogue to the Blowing Up Lemma [7] has not been discovered. Also other methods failed. However the
Wringing Technique, a powerful technique of [4], could be extended
In [P20] to the quantum case and then gave the desired strong converse. We expect
that the work not only
helps us to better understand quantum multiple access channels, but also
brings new ideas and techniques into the whole area of quantum multi-user information
theory.
We conclude now with the second paper [P21].
We prove that the average error capacity 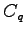 of a quantum
arbitrarily varying channel (QAVC) equals 0
or else the random code
capacity
of a quantum
arbitrarily varying channel (QAVC) equals 0
or else the random code
capacity 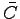 (Ahlswede's dichotomy).
We also establish a necessary and sufficient condition for
(Ahlswede's dichotomy).
We also establish a necessary and sufficient condition for 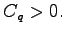 It is interesting to note, that in our proof of Theorem 1 we
essentially use the elimination technique (an early candidate of what
is now called derandomization in Computer Sciences) from [2], which
gives Lemma 2. This is the analogue of the main result of [2]. There a
necessary and sufficient condition for positivity of the capacity was
given, if the set of transmission matrices is row-convex closed-
that is under a practically satisfactory assumption of robustness. The
mathematical problem of characterizing positivity without this
assumption in terms of symmetrizability was started in [18] and
completely solved in [16] with a non-standard decoding rule and without
use of the elimination technique of [2]. (Using this technique and
proving directly that non-symmetrizability implies positive capacity
is a basic problem, which is open for more than 20 years!)
On the other hand in the present quantum case we have not found a
suitable decoding rule and follow the elimination technique
(Lemma 2). Analogously the positivity problem for the QAVC can be
settled by reducing it to a related classical AVC to which then the
result of [16] can be applied.
We emphasize that the very hard maximal error capacity problem for
AVC (including Shannon's zero error capacity problem as special case)
is based on a more realistic communication model. It was solved for a
nice class of channels in [3],
where for the first time in the area of AVC a non standard decoding
rule was used. Extension to QAVC constitutes a challenging problem!
It is interesting to note, that in our proof of Theorem 1 we
essentially use the elimination technique (an early candidate of what
is now called derandomization in Computer Sciences) from [2], which
gives Lemma 2. This is the analogue of the main result of [2]. There a
necessary and sufficient condition for positivity of the capacity was
given, if the set of transmission matrices is row-convex closed-
that is under a practically satisfactory assumption of robustness. The
mathematical problem of characterizing positivity without this
assumption in terms of symmetrizability was started in [18] and
completely solved in [16] with a non-standard decoding rule and without
use of the elimination technique of [2]. (Using this technique and
proving directly that non-symmetrizability implies positive capacity
is a basic problem, which is open for more than 20 years!)
On the other hand in the present quantum case we have not found a
suitable decoding rule and follow the elimination technique
(Lemma 2). Analogously the positivity problem for the QAVC can be
settled by reducing it to a related classical AVC to which then the
result of [16] can be applied.
We emphasize that the very hard maximal error capacity problem for
AVC (including Shannon's zero error capacity problem as special case)
is based on a more realistic communication model. It was solved for a
nice class of channels in [3],
where for the first time in the area of AVC a non standard decoding
rule was used. Extension to QAVC constitutes a challenging problem!
B.1
A Kruskal-Katona type theorem has been proved in [P25] for intersecting families.
Namely, let 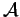 be a
be a 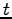 -intersecting family of
-intersecting family of 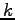 -sets over the set of
positive integers. For given
-sets over the set of
positive integers. For given 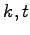 and
and 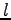 we give an exact lower bound for the
-shadow of
, if
is big enough. Moreover, we give the
configuration of an optimal family, which turns to be one of ``Frankl's
families''. (ad (19))
we give an exact lower bound for the
-shadow of
, if
is big enough. Moreover, we give the
configuration of an optimal family, which turns to be one of ``Frankl's
families''. (ad (19))
[P26] contains the simplest proof for Katona's Intersection Theorem. (ad (19))
A communication network is modelled as an acyclic directed graph
 with some distinguished vertices called inputs and other
distinguished vertices called outputs. The remaining vertices are
called links. There are two parameters of particular interest in
comparing networks: the size and the depth. The size (the number
of edges) in some approximate sense corresponds to the cost of the
network. The depth (the length of the longest path from an input to
an output of the network) corresponds to the delay of the
transmission in the network. Therefore in designing communication
networks it is desirable to achieve smaller size and smaller depth.
An
with some distinguished vertices called inputs and other
distinguished vertices called outputs. The remaining vertices are
called links. There are two parameters of particular interest in
comparing networks: the size and the depth. The size (the number
of edges) in some approximate sense corresponds to the cost of the
network. The depth (the length of the longest path from an input to
an output of the network) corresponds to the delay of the
transmission in the network. Therefore in designing communication
networks it is desirable to achieve smaller size and smaller depth.
An 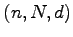 -connector or rearrangeable network is a network with
-connector or rearrangeable network is a network with 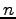 inputs,
inputs, 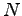 outputs and depth
outputs and depth 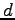 , in which for any injective
mapping of input vertices into output vertices there exist
vertex-disjoint paths joining each input to its corresponding output.
The problem of designing optimal connectors goes back to works of
Shannon, Slepian et al. ([24], [25], [14], [10]) started in the 50's. In [P26] asymmetric connectors
(connectors with
, in which for any injective
mapping of input vertices into output vertices there exist
vertex-disjoint paths joining each input to its corresponding output.
The problem of designing optimal connectors goes back to works of
Shannon, Slepian et al. ([24], [25], [14], [10]) started in the 50's. In [P26] asymmetric connectors
(connectors with 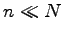 ) of depth two are considered. A simple
combinatorial construction of sparse connectors is given, which is based
on the Kruskal/Katona Theorem for shadows of families of
-element subsets.
Fault-tolerance of the constructed connectors is also considered.
Further improvements were obtained in [P28] by using other theorems for shadows.
The results are in general and also in most special cases the presently best.
) of depth two are considered. A simple
combinatorial construction of sparse connectors is given, which is based
on the Kruskal/Katona Theorem for shadows of families of
-element subsets.
Fault-tolerance of the constructed connectors is also considered.
Further improvements were obtained in [P28] by using other theorems for shadows.
The results are in general and also in most special cases the presently best.
We found the asymptotics of the number of labelled uniform hypergraphs with given degree sequences in [P29]
by using a new switching algorithm. [P30] gives progress on Young Tableaux and [P31] generalizes work
of V. Blinovsky from Hamming to general sum-type metric spaces. The rate-wise optimal results
find applications to search with lies with general cost constraints introduced in [P57].
B.2
Problem: At most how many (0,1)-vectors of given weight can be embedded in a
-dimensional subspace of
 ?
?
Solving in [P34] this long standing geometrical
extremal problem first raised by Longstaff (1977) and by Odlyzko (1981)
was the starting point for developing a new area : Extremal Problems under
Dimension Constraints. Some recent results, conjectures and research problems
can be found in [P35], [P36] and forthcoming work in J. Comb. Theory on Intersecting systems under dimension
constraints. (ad (22))
An extremal problem raised by Bohman in connection to a sum packing problem
of Erdös was studied in [P37].
In particular, we disproved Bohman's conjecture stating a new
conjecture for this problem.
(ad (26))
A very basic inequality, known as the
Ahlswede-Daykin inequality and called Four Function Theorem
by some authors,
which is more general and also sharper than known correlation inequalities
in Statistical Physics, Probability Theory, Combinatorics and Number Theory (see the preface
and survey by Fishburn and Shepp [19])
is extended elegantly to function spaces in [P32].
That is, the inequality of the same type holds for a Borel measure
on ![$ R^{[0,1]}$](img62.png) . We expect that it will have wide applications.
. We expect that it will have wide applications.
It seems that with [P33] a new direction started.
In the last century together with Levon Khachatrian we established a
diametric theorem in Hamming space
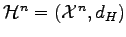 .
Now we contribute a diametric theorem for such spaces, if they are
endowed with the group structure
.
Now we contribute a diametric theorem for such spaces, if they are
endowed with the group structure
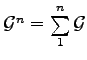 , the direct
sum of group
, the direct
sum of group
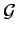 on
on
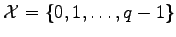 , and as candidates are
considered which form a subgroup of
, and as candidates are
considered which form a subgroup of
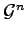 .
For all finite groups
, every permitted distance
, and all
.
For all finite groups
, every permitted distance
, and all
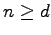 subgroups of
with diameter
have maximal
cardinality
subgroups of
with diameter
have maximal
cardinality 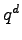 .
Other extremal problems can also be studied in this setting.
.
Other extremal problems can also be studied in this setting.
B.3
It was planned to continue with A. Sárközy our investigations of extremal sets of numbers, especially
primitive sets.
Unfortunately, various obligations prohibited to work on the problems (33)-(44), but we still want to
do it! On the other hand, occasional meetings in Luminy and in Bielefeld, also with C. Mauduit and J. Cassaigne, led
to nice number theoretical contributions to Cryptology.
The papers are devoted to the investigation of the problem of
generating pseudorandom sequences and their statistical properties.
This is an important task for cryptology since for instance these pseudorandom
sequences can serve as a source of key bits needed for encryption. The
first problem in [P40] is to find a proper test for sequences
of elements from a finite alphabet to be pseudorandom.
For a binary sequence with alphabet
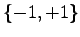 the authors choose the criterium of a small modul of the sum of subsets of the elements of the sequence maximized
over the choice of the subset of positions of these elements and small correlation measure
which is the absolute value of the sum of products of elements from some set of subsets of
positions maximized over the special choice
of the positions of these elements.
Then these measures are extended in [P41]
to a nonbinary alphabet and as one generalization the frequency criterium is chosen, i.e.
the deviation of the number of given patterns
on given positions from the expected value, maximized over the choice of the positions.
Relations are proved which show the equivalence (in some sense)
of these different tests of pseudorandomness in the binary case.
Also proved is that the number of the sequences with large measures of pseudorandomness is
exponentially small in comparison with the number of all sequences.
Algorithms were introduced in for constructing pseudorandom sequences.
These constructions can find applications in cryptology and simulations.
Also considered were
the notion of
the authors choose the criterium of a small modul of the sum of subsets of the elements of the sequence maximized
over the choice of the subset of positions of these elements and small correlation measure
which is the absolute value of the sum of products of elements from some set of subsets of
positions maximized over the special choice
of the positions of these elements.
Then these measures are extended in [P41]
to a nonbinary alphabet and as one generalization the frequency criterium is chosen, i.e.
the deviation of the number of given patterns
on given positions from the expected value, maximized over the choice of the positions.
Relations are proved which show the equivalence (in some sense)
of these different tests of pseudorandomness in the binary case.
Also proved is that the number of the sequences with large measures of pseudorandomness is
exponentially small in comparison with the number of all sequences.
Algorithms were introduced in for constructing pseudorandom sequences.
These constructions can find applications in cryptology and simulations.
Also considered were
the notion of 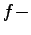 complexity
of the set of
complexity
of the set of 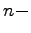 tuples which is the maximal number
s.t. arbitrary
positions
have an arbitrary pattern in some
tuple from this set, which was introduced in [P39] and
correlation properties of binary sequences ([P42]).
tuples which is the maximal number
s.t. arbitrary
positions
have an arbitrary pattern in some
tuple from this set, which was introduced in [P39] and
correlation properties of binary sequences ([P42]).
More explanations are given by the excellent introductions also in earlier work, where C. Mauduit and
A. S'arközy explain their approach to cryptology. Roughly speaking their philosophy is that
less can be more:
instead of going after complex problems whose high complexity till now cannot be proved and therefore always there can be
a bad end of a dream, they suggest to work with number theoretical functions of likely not highest complexity,
but for which some degree of complexity can be proved.
Together with V. Blinovsky classical number theoretical extremal theory was advanced in [P43].
A decade ago Ahlswede and Khachatrian settled a problem of Erdös
about maximal sets of positive integers less than
not containing
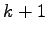 pairwise coprimes and also a problem of Erdös and Graham
concerning the maximal value of
with integers
pairwise coprimes and also a problem of Erdös and Graham
concerning the maximal value of
with integers
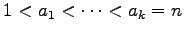 ,
,
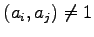 . Actually this problem was solved in a more general
and seemingly more natural setting reflected in the phrase ``having
divisors from a specified set of primes''.
All this work, related work and the history of the problems is
reported in the survey [P24].
The present work is indicated in our title, which refers to a common
generalization of both these problems and their corresponding theorems.
. Actually this problem was solved in a more general
and seemingly more natural setting reflected in the phrase ``having
divisors from a specified set of primes''.
All this work, related work and the history of the problems is
reported in the survey [P24].
The present work is indicated in our title, which refers to a common
generalization of both these problems and their corresponding theorems.
These authors also found an extension to algebraic number fields [P43].
There they prove that for all sufficiently large 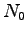 the maximal
set of ideals of the maximal order of the algebraic number field,
such that any pair of ideals from this set is not coprime and norm
of each ideal does not exceed
is the set
the maximal
set of ideals of the maximal order of the algebraic number field,
such that any pair of ideals from this set is not coprime and norm
of each ideal does not exceed
is the set
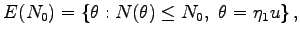 where
where
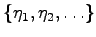 is the set of prime ideals of the
maximal order and
is the set of prime ideals of the
maximal order and
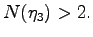
The famous Green/Tao result says that the primes have arbitrary long arithmetical progressions.
Subsequently Tao found a novel connection:
Information Theory as tool for Graph Theory and Number Theory
The final form of Tao's inequality relating conditional
expectation and conditional mutual information
Recently Terence Tao ([26]) approached Szemerédi's Regularity Lemma from
the perspectives of Probability Theory and of Information Theory
instead of Graph Theory and found a stronger variant of this lemma,
which involves a new parameter.
To pass from an entropy formulation to an expectation formulation he
found the following
Lemma.
Let 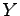 , and
, and 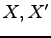 be discrete random variables taking values in
be discrete random variables taking values in
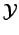 and
and
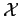 , respectively, where
, respectively, where
![$ \mathcal Y\subset[-1,1]$](img83.png) , and with
, and with 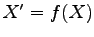 for a
(deterministic) function
for a
(deterministic) function 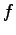 .
.
Then we have
We show that the constant 2 can be improved to
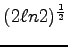 and
that this is the best possible constant.
and
that this is the best possible constant.
B.4
Enrichments for the project are gained from relations between coding for channels
with feedback and search problems (c.f. [8]).
For example error-correcting codes with feedback, which were introduced by Berlekamp [11]
are equivalent
to the following search problem. A search space
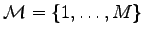 is given and we want to find
one (say defective) element. In every step we perform a test by choosing a subset of
is given and we want to find
one (say defective) element. In every step we perform a test by choosing a subset of 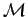 .
When working correctly the test produce a ``Yes'', if the defective element is in the subset
and otherwise it produces a ``No''.
The main problem is that the tests not always give the correct answer.
In our model we assume that the number of incorrect answers is restricted.
.
When working correctly the test produce a ``Yes'', if the defective element is in the subset
and otherwise it produces a ``No''.
The main problem is that the tests not always give the correct answer.
In our model we assume that the number of incorrect answers is restricted.
This search model is often described
equivalently as ``Renyi-Berlekamp-Ulam-Game''.
The models readily extends to
alternatives for answers
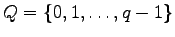 .
The new idea, which was developed in [P49], is to consider error cost constraints. That means, there is a
function
.
The new idea, which was developed in [P49], is to consider error cost constraints. That means, there is a
function
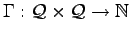 . The function
. The function 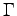 is meant to
weigh the answers. Whenever an answers
to a question (a test), whose answer is
is meant to
weigh the answers. Whenever an answers
to a question (a test), whose answer is 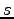 ,
is given the answer has weight
,
is given the answer has weight
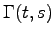 . It is allowed to give false answers with total weight
up to
. It is allowed to give false answers with total weight
up to 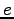 .
.
In [P52] the authors assume some
symmetry of
and weights 0 and 1. They provide a lower bound on the number of questions needed to
solve the problem and prove that in infinitely many cases this bound is attained by (optimal) search
strategies. Moreover they prove that, in the remaining cases, at most one question
more than the lower bound is always sufficient to successfully find the unknown element.
All strategies also enjoy the property that among all possible adaptive strategies
they use the minimum amount of adaptiveness during the search process.
In [P54] the general weighted case is considered. We give an asymptotically exact solution if the
positive minimal weight 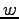 of
is a divisor of
.
of
is a divisor of
.
A coding scheme for delayed feedback,
which shows that in this case the capacities of all memoryless channels with non-delayed
feedback can be achieved, is given in [P47].
A characterization of the zero-error capacity of a
DMC and the average-error capacity of an AVC, when the delay time increases linearly with the
length of the codes, is also obtained.
In [P46]
the Kraft inequality for d-DBS codes
is sharpened, based on the work of Ambains-Bloch-Schweizer, who introduced these codes.
A new suffix sorting algorithm to sort all suffixes of a
string
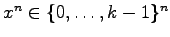 lexicographically is developed in [P48].
It computes the
suffix sorting in
lexicographically is developed in [P48].
It computes the
suffix sorting in 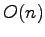 space and
space and 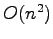 time in the worst case.
It has also the property that it sorts the suffixes lexicographically correctly
according to the prefixes of length
time in the worst case.
It has also the property that it sorts the suffixes lexicographically correctly
according to the prefixes of length
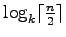 in the worst case in linear time.
in the worst case in linear time.
Already in his Lectures on Search Renyi suggested to consider a search
problem, where an unknown
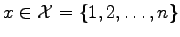 is to be found by
asking for containment in a minimal number
is to be found by
asking for containment in a minimal number 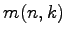 of subsets
of subsets
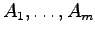 with the restrictions
with the restrictions
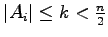 for
for
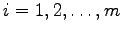 .
.
Katona gave in 1966 the lower bound
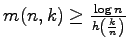 in terms of binary
entropy and the upper bound
in terms of binary
entropy and the upper bound
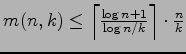 ,
which was improved by Wegener in 1979 to
,
which was improved by Wegener in 1979 to
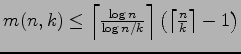 .
We prove here for
.
We prove here for 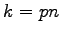 that
that
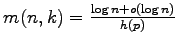 , that is,
ratewise optimality of the entropy bound:
, that is,
ratewise optimality of the entropy bound:
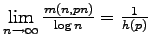 .
Actually this work was motivated by a more recent
study of Karpovsky, Chakrabarty, Levitin and Avresky of a problem on
fault diagnosis in hypercubes,
which amounts to finding the minimal number
.
Actually this work was motivated by a more recent
study of Karpovsky, Chakrabarty, Levitin and Avresky of a problem on
fault diagnosis in hypercubes,
which amounts to finding the minimal number 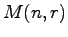 of Hamming balls
of radius
of Hamming balls
of radius 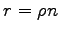 with
with
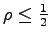 in the Hamming space
in the Hamming space
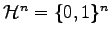 , which separate the vertices.
Their bounds on
are far from being optimal.
We establish bounds implying
, which separate the vertices.
Their bounds on
are far from being optimal.
We establish bounds implying
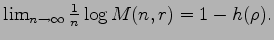 However, it must be emphasized that the methods of prove for our two
upper bounds are quite different.
However, it must be emphasized that the methods of prove for our two
upper bounds are quite different.
In [P57] we consider the question, whether there
exists a fix-free code for a given sequence of codeword lengths.
We introduce general 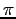 -systems, which are special kinds of fix-free codes
with Kraftsum
-systems, which are special kinds of fix-free codes
with Kraftsum
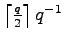 .
We show, that
-systems with only
two neighbouring levels and
.
We show, that
-systems with only
two neighbouring levels and
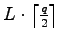 codewords on the first level
exist, if and only if
there exists a
codewords on the first level
exist, if and only if
there exists a
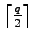 -regular subgraph of
the directed de Bruijn graph
-regular subgraph of
the directed de Bruijn graph
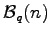 with
edges over a
-ary alphabet with
with
edges over a
-ary alphabet with 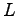 vertices.
Furthermore we show that arbitrary one level
-systems exist.
With this method the range of validity of the
vertices.
Furthermore we show that arbitrary one level
-systems exist.
With this method the range of validity of the
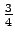 -conjecture was significantly enlarged.
-conjecture was significantly enlarged.
A famous problem in coding theory consists in finding good bounds for
the maximal size, say 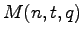 , of a
-error correcting code
over a
-ary alphabet
, of a
-error correcting code
over a
-ary alphabet
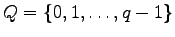 with blocklength
.
Suppose now that having sent letters
with blocklength
.
Suppose now that having sent letters
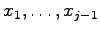 the encoder
knows the letters
the encoder
knows the letters
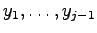 received before he sends the
next letter
received before he sends the
next letter 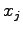 (
(
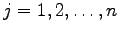 ). We then have the presence of a
noiseless feedback channel.
We investigate in [P58] the
-ary case. Again
the Hamming bound for
). We then have the presence of a
noiseless feedback channel.
We investigate in [P58] the
-ary case. Again
the Hamming bound for
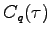 , the maximal rate achievable for
, the maximal rate achievable for
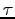 and all large
, is a central concept.
For the feedback model we present here a coding scheme based on an idea
of deletions. It is easy to analyse and yield also Berlekamp's results
for the case
.
We turn now to the model with localized errors. Suppose that the encoder, who wants
to encode message
and all large
, is a central concept.
For the feedback model we present here a coding scheme based on an idea
of deletions. It is easy to analyse and yield also Berlekamp's results
for the case
.
We turn now to the model with localized errors. Suppose that the encoder, who wants
to encode message
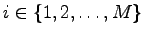 , knows the
-element set
, knows the
-element set
![$ E\subset [n]=\{1,\ldots ,n\}$](img133.png) of positions, in which only errors may
occur. He then can make the codeword presenting
of positions, in which only errors may
occur. He then can make the codeword presenting 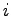 dependent on
dependent on
![$ E\in\mathcal E_t=\binom{[n]}t$](img135.png) , the family of
-element subsets of
, the family of
-element subsets of ![$ [n]$](img136.png) .
Whereas all this work is for block codes we next
investigate variable length codes with all lengths bounded from above
by
. The end of a word carries the symbol
.
Whereas all this work is for block codes we next
investigate variable length codes with all lengths bounded from above
by
. The end of a word carries the symbol  and is thus
recognizable by the decoder. Very important here is that the lengths
carry sure data which can be used as a ``protocol'' information.
For both, the
-model with feedback and the
-model with
localized errors, the Hamming bound is the exact capacity curve for
and is thus
recognizable by the decoder. Very important here is that the lengths
carry sure data which can be used as a ``protocol'' information.
For both, the
-model with feedback and the
-model with
localized errors, the Hamming bound is the exact capacity curve for
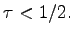 Somewhat surprizingly, whereas with feedback the
capacity curve coincides with the Hamming bound also for
Somewhat surprizingly, whereas with feedback the
capacity curve coincides with the Hamming bound also for
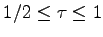 , in this range for localized errors the capacity
curve equals 0.
Also notice that without the marker
in the range
, in this range for localized errors the capacity
curve equals 0.
Also notice that without the marker
in the range
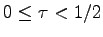 with feedback the capacity curve is smaller
than that for localized errors.
Also we give constructions in the
-model with both, feedback
and localized errors.
Finally, in the standard model with feedback and localized
errors the help of feedback is adressed. We give an optimal construction for
one-error correcting codes with feedback and localized errors.
with feedback the capacity curve is smaller
than that for localized errors.
Also we give constructions in the
-model with both, feedback
and localized errors.
Finally, in the standard model with feedback and localized
errors the help of feedback is adressed. We give an optimal construction for
one-error correcting codes with feedback and localized errors.
C.1
A broad class of statistical problems arises in the framework of
hypothesis testing in the spirit of identification for different kinds of sources,
with complete or partial side information or without it.
[P60] is devoted to the investigation of a hypothesis testing problem
for arbitrarily varying sources with complete side information.
[P59] considers the more difficult but more promising problem of
hypothesis identification.
C.2
In [P61] readers find an interesting application of Information
Theory in the study of Language Evolution. The model was originally
introduced by M.A. Nowak and D.C. Krakauer [23], where the
fitness of a language is introduced. For this model they showed
if signals can be mistaken for each other,
then the performance of such systems is limited.
The performance cannot be increased over a fixed threshold by adding
more and more signals. Nevertheless the concatenation of signals or
phonemes to words increases significantly the fitness of the
language. The fitness of such a signalling-system depends on the
number of signals and on the probabilities to transmit individual
signals correctly. R. Ahlswede, E. Arikan, L. Bäumer and C. Deppe investigated optimal
configurations of signals in different metric spaces. In [P61] we prove for all
metrics with a positive semidefinite associated matrix a conjecture
by Nowak including all important metrics
studied by different authors in this direction.
The conjecture holds for all ultra-metric spaces.
Especially the authors analyze
the Hamming space. In this space the direct consequence of the theorem
is that the fitness of the whole space equals the maximal
fitness and the fitness of Hamming codes asymptotically
achieves this maximum.These theoretical models of fitness of a language enable the
investigations of traditional information theoretical problems in this
context, in particular, for feedback problems,
transmission problems for multi-way channels etc.
It is shown that feedback increases the fitness of a language.
C.3
The paper [P62] has been discussed in 2.1.
C.4
In the recent paper [P61] it is shown that the work under B.2 finds
applications in Statistical Database Security
(see [20]) and settles several of the problems there.
Fortsetzungsantrag
In the short phase of the sequel proposal (31.8.2006-29.2.2008) only some tasks could be
worked on with the granted resources (7 BAT IIa positions for one year were applied for and
1.5 positions for one year could be given).
Progresses were achieved in
B.1 (Development of Methods: Inequalities and Extremal Problems)
B.4 (Search and Sorting),
and C.4 (Security in Database),
which are explained beneath.
B.1
Ahlswede and Soloveva considered in [P63] .........
B.4
In [P64] we close the gap between the bounds of [P54] (see first phase B.4) and provide
matching upper and lower bounds also if
is not a divisor of
.
C.4
A statistical database (SDB), considered in [P65], is a database that is used to return
statistical information derived from the
records to user queries for statistical data analysis.
Sometimes, by correlating enough statistics, confidential data
(stored in a SDB) about an individual can be inferred.
Examples of confidential information stored in a SDB might be salaries
or data concerning the medical history of individuals.
An important problem is to provide security to SDB
against the disclosure of confidential information.
A statistical database is said to be secure if no protected data can be
inferred from the available queries.
One of the security-control methods suggested in the literature
consists of query restriction:
the security problem is to limit the use of the SDB, introducing
a control mechanism, such that no protected data
can be obtained from the available queries.
Chin and Ozsoyoglu [13] introduced a control mechanism,
called Audit Expert, where
only SUM queries, that is only certain sums of individual records,
are available for the users. This SUM query model leads to several
challenging optimization problems.
Assume there are
numeric records
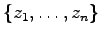 stored in a database.
A natural problem is to maximize the number of answerable SUM queries,
that is the number of subset sums
of
(possibly with some additional constraints)
that can be returned, such that none of numbers
stored in a database.
A natural problem is to maximize the number of answerable SUM queries,
that is the number of subset sums
of
(possibly with some additional constraints)
that can be returned, such that none of numbers 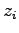 (or sums of
subsets with the size not exceeding a specified number)
can be inferred from these queries. In [P58] tight bounds , for the number
of answerable queries, under constraints on size and dimension on inquired subsets, are obtained.
We considered the problem for the
(or sums of
subsets with the size not exceeding a specified number)
can be inferred from these queries. In [P58] tight bounds , for the number
of answerable queries, under constraints on size and dimension on inquired subsets, are obtained.
We considered the problem for the 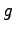 -group security model, where not only individual data
but also subset sums of size
or less must be protected. Earlier only
results for
-group security model, where not only individual data
but also subset sums of size
or less must be protected. Earlier only
results for 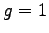 were known. In case when the size of query sets is fixed we
give exact solution to the problem and describe all optimal query sets.
(The results was also presented
at Dagstuhl Seminar 06201, Combin. and Algoritmic Foundations of
Pattern and Association Discovery, 14 - 19, Mai, 2006). These results are heavily based
on methods and tools from [5]. They
improve previously known results in [12], [17] and extend them to higher dimension.
In particular, a question raised by Griggs [20] is solved.
were known. In case when the size of query sets is fixed we
give exact solution to the problem and describe all optimal query sets.
(The results was also presented
at Dagstuhl Seminar 06201, Combin. and Algoritmic Foundations of
Pattern and Association Discovery, 14 - 19, Mai, 2006). These results are heavily based
on methods and tools from [5]. They
improve previously known results in [12], [17] and extend them to higher dimension.
In particular, a question raised by Griggs [20] is solved.
Noch nicht bearbeitete Teilgebiete für Informationsflüsse wurden im gegenwärtigen Antrag
des DFG-Projektes ``Informationflüsse'' - wie dort unter 2.1 erläutert - mit aufgenommen.
|