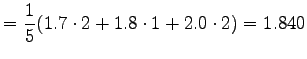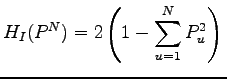FAKULTÄT FÜR MATHEMATIK |
|
Interaktive Kommunikation, Diagnose und Vorhersage in Netzwerken
Darstellung der erreichten Ergebnisse
Erstantrag
I Interaktive Kommunikation
A Interaktive Datenübertragung
1. Informationsflüsse
Unser Vortrag am 23.07.2002 in Konstanz konzentrierte sich auf den Min-Max Satz aus [5] über Informationsflüsse in Netzwerken. Neben dem üblichen Kopieren von Daten ist auch Codieren von weiterem Vorteil und führt zu einem optimalen Ergebnis. Damit ist der Unterschied von Informationsflüssen und Güterflüssen in Netzwerken vollständig verstanden. Während die Multi-user Informationstheorie für die wir den ersten Kanalcodierungssatz bereitstellten ([A12], [A18], []), mit Schwierigkeiten stochastischer Störungen und Korrelationen kämpfte und nur kleine Zahlen von Sendern und Empfängern behandeln konnte, zeigt der neue Satz, dass auch schon für störungsfreie Kanäle echte Probleme entstehen und gelöst werden konnten - und zwar für ganze Netzwerke von Kommunikatoren. Inspiriert durch den Vortrag haben Peter Sanders und seine Koautoren S. Egner und L. Tolhuizen [] den Existenzsatz um einen effizienten Algorithmus bereichert (Vortrag ``Polynomial time algorithms for networks information flow'' am 27.03.2003 in Tübingen). Dieses Ergebnis und die Arbeiten unseres langjährigen Mitarbeiters Ning Cai und Koautoren ([P1], [P2]), die den Min-Max Satz in Standardrichtungen (z.B. für störende aber unabhängige Kanäle) weiterführen, wurden auf dem von den zwei vom DFG geförderten Miniworkshops mit den Teilnehmern diskutiert. Neuere weiterführende Forschungsvorhaben werden in Sektion 3 formuliert. Es wurden 15 Vorträge gehalten, die in Anlage 4 zu finden sind.
2. Konnektoren
Der Beitrag der Kieler Baltz, Jäger und Srivastav [9] über Konnektoren die Bielefelder Gruppe besonders angeregt (Vortrag von Anand Srivastav ``Algorithms and Design for Multicast Networks'' am 27.03.2003 in Tübingen) und zu den Arbeiten [P15] und [P3] geführt. Das Problem des Entwurfs von optimalen Konnektoren (``rearrangeable networks'') geht auf die Pionierarbeiten von Shannon [21], Slepian [22], Clos [12] und Benes [10] zurück.
Gegeben
Ein
Ein Graph
4. Zufällige Verbreitung in Netzwerken (Random Walks)
Da vom kombinatorischen Standpunkt aus ein Netzwerk ein Graph
(Hypergraph) mit gewichteten Kanten ist, ist die Untersuchung von
Eigenschaften von Graphen von Interesse. In der aktuellen Arbeit [A194]
haben wir gezeigt, wie unser Resultat über die Zahl von
gekennzeichneten Hypergraphen angewendet werden kann, um das Volumen
des gigantischen ``Process-Level Large Deviations'' für stückweise homogene Random Walks spielen eine Schlüsselrolle bei der Untersuchung von probabilistischen Eigenschaften der Verbreitung von Daten in Netzwerken. Das normale Schema von zwei Flüssen wird beschrieben durch einen Random Walk in zwei Halbräumen mit unterschiedlichen Dynamiken in jedem Raum. Das Problem der grossen Abweichungen wurde für diesen Fall in [11] gelöst. Gleichzeitig ist dieses Problem im Falle von mehr als zwei homogenen Teilen weitaus schwieriger und nur wenig ist darüber bekannt.
5. Kommunikationskomplexität
In diesem Gebiet sind keine Arbeiten entstanden. In den 80-er Jahren haben wir intensiv auf diesem Gebiet gearbeitet. Erinnert sei an die Arbeiten ([A61], [A81], [A82], [A88], [A93], [A120]). Ferner sei auf inzwischen umfangreiche Lehrbuchliteratur verwiesen.
B Interaktive Codierungstheorie
Bereits im Erstantrag wurde auf eine Erweiterung der algebraischen Codierungstheorie für mehrere Sender und Empfänger hingewiesen. Die Ergebnisse der bereits erwähnten Arbeit [5] legen es nahe Informationsflüsse in Netzwerken zu untersuchen, die oben genannten Typen von Fehlern unterliegen.
1. Unkonventionelle Fehler und Kodierungen
Es gibt verschiedene unkonventionelle Konzepte von Fehlern wie unidirektionale Fehler, Defekte, Löschungen, Einsetzungen, unsynchronisierte Fehler, lokalisierte Fehler usw., die unkonventionelle Codes zur Erkennung und Korrektur benötigen.
In der Arbeit [P5] haben wir
Wir betrachten eine spezielle Art von asymmetrischen Fehlern in einem
Theorem 1 (i) Für
Zunächst betrachten wir Codes, die über eine gewisse lineare
Gleichung über den reellen Zahlen definiert sind. Gegeben
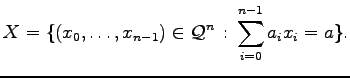
Für gegebene
Theorem 2
Theorem 3
(i) Für
Das Problem des Schutzes gegen unidirektionale Störungen entsteht in Systemen mit
optischer Nachrichtenübertragung, beim Entwurf von fehlertoleranten sequentiellen Maschinen,
in asynchronen Systemen usw.
2. Synchronisation und Delay
In [P19] werden Synchronisationscodes mit konstanter Blocklänge
Ein binäres deBruijn Netzwerk der Ordnung
C Interaktive Identifikation
1. Allgemeine Theorie des Informationstransfers, gemeinsame Zufälligkeit (Common Randomness), Zufallszahlen
Alle hier dargestellten Ergebnisse wurden in Kooperation mit dem DFG-Projekt AH46/1-1,1-2, 4-1 erzielt. Ausserdem soll die Forschung in einem neubeantragten DFG-Projekt fortgeführt werden.
Nehmen wir an, eines von
Die Theorie ist inzwischen in verschiedene Richtungen weit entwickelt
worden. Sie ist von mehreren Autoren (Anantharam, Bassalygo, Bäumer,
Burnashev, Cai, Csiszár, Han, Kleinewächter, Narayan, van der Meulen,
Verboven, Verdu, Yang, Zhang).
Fundamentale Phänomene sind:
Die Theorie der Identifikation fand interessante Anwendungen bei Alarmsystemen ([]) und Wasserzeichen ([], [], []). Wie in [] herausgestellt wurde ist die Kombination von Übertragungscodes und Identifikationscodes nützlich für gewisse Aufgaben der Identifikation über einen ``multiple-access'' Kanal. Dies kann z.B. für öffentliche Notdienste zutreffen, die in einem Gebiet viele Arten von verschiedenen Anfragen einer großen Zahl von Individuen versorgen, die für sich genommen selten eine kurze Nachricht gefolgt von einer Anfrage senden. Unter Wasserzeichensignierung versteht man eine Methode, geheime Information in eine Nachricht (z.B. ein Bild) einzubetten, die weder entfernt noch dekodiert werden kann ohne Zugriff auf den geheimen Schlüssel. Dieses kann zum Schutz von Urheberrechten eingesetzt werden. Eine sehr ausführliche Liste mit Referenzen hierzu findet man in [A186].
2. Watermarking
Wir haben in [P7] die Untersuchungen von Y. Steinberg und N. Merhav fortgesetzt und insbesondere einige ihrer Fragen zur Robustheit bei Watermarking-Identifikations Codes beantwortet. Beim Watermarking geht es darum, eine geheime Information in einer gegebenen Nachricht zu verbergen, so dass diese von jemandem, dem der geheime Schlüssel unbekannt ist, nicht entfernt und entschlüsselt werden kann. Y. Steinberg und N. Merhav regten an, die folgenden Fälle zu untersuchen.
Da die Internet-Technologie sich so schnell entwickelt, ist der Schutz des Urheberrechts offensichtlich von immer größerer Bedeutung. Wir bemerken hier, dass nach unserer Kenntnis der Angriffs-Kanal in [A186] zu den robustesten der in dieser Richtung untersuchten zählt. In der Arbeit [P8] werden Anwendungen von Watermarking ausführlich dargestellt.
3. Identifizierbare Eltern Eigenschaft (IPP, identifiable parent property)
Um gegen Software Piraterie geschützt zu sein, haben
H.D.L. Hollmann, J.H. van Lint, J-P. Linnartz, und
L.M.G.M. Tolhuizen in [13] Codes mit identifizierbarer
Eltern Eigenschaft (IPP) wie folgt eingeführt.
Es sei
R. Ahlswede und N. Cai [P9] bemerkten, dass das Problem in [13]
als das folgende Kommunikationsproblem für Multiple-Access Kanäle
(MAC) umformuliert werden kann. Sei
D Broadcasting
In [P10] betrachten wir ein Kommunikationssystem mit einem Sender (oder Kodierer)
Diese Folge wird an die zwei Empfänger über zwei unabhängige Kanäle geschickt. Wegen der Störung des Kanals kann die Ausgabefolge, die von den zwei Empfängern erhalten wurde, in höchstens
Wir präsentieren einen Code der eine bessere Rate als der in [8] gibt, wobei Feedback nur einmal während der gesamten Übertragung benutzt wird. Die Idee ist es, die Weitere Probleme aum Broadcasting sollen im neubeantragten Projekt ``Informationsflüsse'' untersucht werden.
II Diagnose
Die in diesem Abschnitt beschriebenen Suchprobleme sollen in einem neubeantragten Projekt weiter untersucht werden. 1. Diagnose als Suchen mit beschränkten Mengen
Bei der Analyse der Arbeit [15] zur Überdeckung von Knoten für die Fehlerdiagnose im Hyperkubus
haben wir bemerkt, dass die Essenz ein Suchproblem darstellt
mit Restriktionen an die Teilmengen
Schon Renyi fragte nach dem minimalen trennenden System
Katona gab eine Entropieschranke als untere Schranke für
Überraschenderweise - diese Resultate nun schon seit mehreren Dekaden kennend - interessierte uns nun, ob diese Entropieschranke scharf ist, wenigstens approximativ und wir waren in der Lage dies zu beweisen ([P28]). Während eine standardmäsige zufällige Wahl der Menge selbst bei nicht beschränkten Mengen bekanntlich ([]) um einen Faktor 2 vom Optimum entfernt ist, gelingt jetzt die Lösung mit nur einigen Experten bekannten Expurgationstechnik der Informationstheorie.
Ferner, wenn die Teilmengen durch Hammingkugeln in
2. Delay
Als nächstes fassen wir die Ergebnisse der Arbeit [P11] zusammen.
Das wird in Kapitel 3 des Buches [] von R. Ahlswede und I. Wegener beschrieben. Dort werden auch Ahlswedes Kodierungsschema für den DMC und auch für beliebig variierende Kanäle (AVC) beschrieben, die die Kapazitäten erreichen. Das letztere kann als robustes Modell der Suche angesehen werden.
In [P11] haben wir für
3. Sequentielle Suchmodelle mit Fehlern
4. Monotonicity Testing and Property Testing
III Vorhersagetheorie in Netzwerken
Lars Bäumer, dessen Dissertation Vorhersagetheorie in Verbindung mit Identifikation behandelte, hat nicht wie bei der Antragsstellung geplant an diesem Projekt mitgearbeitet, da er mein Forschungsprojekt am Zif als Assistent unterstützt. Er hat sich dort biologischen Fragestellungen zur Evolution von Sprachen und zur Tierkommunikation gewidmet. Vorhersagetheorie wurde deshalb in diesem Projekt nicht betrieben. Die BAT IIa-Stelle dieses Projektes hatte durchgehend Harout Aydinian inne.
IV Zwischenspeicher Managementstrategien in Netzwerken und Creating Order
Christian Wischmann wird dieses Thema in seiner Doktorarbeit behandeln. Seine ersten Ergebnisse präsentierte er auf dem Jahreskolloquium in Aachen 2006.
1.Fortsetzungsantrag
I Interaktive Kommunikation
A Interaktive Datenübertragung
1. Informationsflüsse
Unsere Arbeit [A155] aus dem Jahre 2000 hat
mittlerweile eine neue Forschungsrichtung begründet. Dies wird deutlich, wenn man
sich die ``Network Coding Home Page'' von Ralf Koetter
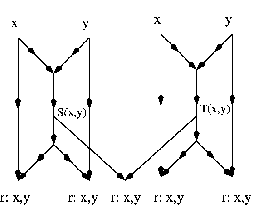
(``http://tesla.csl.uiuc.edu/ Nach der Datenbank von R. Koetter wurden weltweit nur eine handvoll Arbeiten in der Netzcodierung vor dem Jahr 2001, aber dann 8 Arbeiten 2002, 23 Arbeiten 2003 und über 25 Arbeiten in der ersten Hälfte von 2004 veröffentlicht, usw. Die Forschung zur Netzcodierung wächst schnell. Microsoft, IBM und andere Firmen haben Abteilungen eingerichtet, die dieses neue Gebiet erforschen. Einige amerikanische Universitäten (Princeton, MIT, Caltech und Berkeley) haben auch Forschungsgruppen in der Netzcodierung aufgebaut. Der heilige Gral in der Netzcodierung soll (auf eine automatisierte Art und Weise) Netzflüsse (wobei Netzcodierung verwendet wird) in einer durchführbaren Weise planen und organisieren. Die meisten gegenwärtige Forschungen behandeln dieses schwierige Problem noch nicht. Wir berichten hier über die Arbeit [P14], in der weitere grundlegende Erkenntnisse gewonnen wurden. Wir zeigen, daß die Aufgabe des Entwerfens von leistungsfähigen Strategien für Informationsnetzflüsse (Netzcodierungen) eng mit dem Konstruieren von fehlerkorrigierenden Codes zusammenhängt. Siehe dazu insbesondere unten die Proposition 3 in der eine Bijektion zwischen Netzwerkflüssen und einer Klasse fehlerkorrigierender Codes gezeigt wird. Diese Verbindung überrascht, da sie für Netze auftritt, in denen keine Fehler vorkommen! Erinnert sei an die traditionelle Verwendung dieser Codes zum Rückschluss auf Nachrichten, die durch unbekannte Fehler gestört sind. Um in den Reichtum dieser Ideen einzuführen, zeigen wir, dass die Lösung für Flussprobleme für bestimmte einfache Netze mathematisch gleichwertig ist mit der Beantwortung der Frage nach der Existenz orthogonaler lateinischer Quadrate, bei der sich bekanntlich Euler gründlich irrte. Eine vollständige Lösung wurde erst in der zweiten Hälfte des 20ten Jahrhunderts gefunden (``The Euler spoilers'' Bose/Parker/Shrikhande). Gegeben sei das folgende Netz:
Proposition 1 Es gibt eine Bijektion zwischen den Lösungen dieses Flussproblems
und den Paaren der orthogonalen lateinischen Quadrate der Ordnung Proposition 2 (Korollar zur Lösung von Eulers Problem): Das Flussproblem in der Abbildung hat eine Lösung genau dann, wenn das zugrundeliegende Alphabet nicht 2 oder 6 Elemente hat.
Netzcodierung und seine Verbindungen zu fehlerkorrigierenden Codes
Betrachten wir sodann das folgende Flussproblem:
Jeder Kanal in diesem Netz hat die Kapazität eine Nachricht (pro Zeiteinheit)
zu übertragen. Nehmen wir an, die Aufgabe sei, zwei Nachrichten
Das Flussproblem kann verallgemeinert werden. Betrachten wir ein Netz Allgemeiner kann gezeigt werden:
Proposition 3 Das Flussproblem
Diese Codes sind gerade die
Ferner kann man zeigen, dass das Informationsfluss Problem
Sind solche Phänomene nur sporadisch oder weitverbreitet? Für ein anderes Netz mit horizontalen und vertikalen Flüssen kann gezeigt werden, dass optimale vertikale Flüsse einem optimalen Minimalabstand Code entsprechen. Diese wurden in [1] Anticodes genannt und vollständig charakterisiert. Dieses Beispiel ist ein Schlüsselbeispiel, das zeigt, dass die klassische Theorie der fehlerkorrigierenden Codes weiter entwickelt werden muss, um als Grundlage für die Netzcodierung zu dienen. Schlechteste Codes traten schon früher in der Kryptographie auf ([3],[4]). Dieses von uns begründete Forschungsgebiet soll in einem neu beantragten DFG-Projekt ``Informationsflüsse'' weiter erforscht werden.
2. Konnektoren
Ein
In Verfolgung unseres Zieles, den Schattensatz von Kruskal/Katona
für die Posets, die Familien der Teilmengen
einer endlichen Menge sind, durch Schattensätze in anderen Posets zu ersetzen,
kamen wir auf den Satz von Leeb für Posets des Produktes von Sternen und waren damit
erfolgreich. Eine einfache Konstruktion liefern Konnektoren der Größe
Die vorher besten Resultate über die Größe von Konstruktionen von
-
-
-
Ein einfaches probabilistisches Argument (Baltz/Jäger/Srivastav, 2003) zeigt die Existenz
derartiger Konnektoren der Größe
3. Interaktive Datenübertragung zum Zwecke des Rechnens
Es wird folgendes Modell zugrunde gelegt. Die Rechnung heißt privat, wenn kein Prozessor irgendwelche Informationen über die Argumente der anderen bekommen hat. Ziel ist es die Übertragungsdauer für die Berechnung zu minimieren.
In der Diplomarbeit ([P16])
von Frau Laumann wurde unter Anderem ein Algorithmus von Chor und Kushilevitz
für die
4. Zufällige Verbreitung in Netzwerken (Random Walks)
Das im Fortsetzungsantrag 2003 vorgeschlagene Problem wurde gelöst. In [P17] wird die asymptotische Formel für die Anzahl der skalierten Schrittfunktionen mit Einschränkung der Länge und Höhe der Schritte des gegebenen Bereichs in der Nachbarschaft einer gegebenen Kurve (Formen der Young Diagramme) angegeben. Dies erlaubt uns, die Asymptotik der Anzahl solcher Funktionen zu finden.
5. Kommunikationskomplexität
B Interaktive Codierungstheorie
1. Unkonventionelle Fehler und Kodierungen
Das Problem des Schutzes gegen unidirektionale Störungen entsteht in Systemen mit
optischer Nachrichtenübertragung, beim Entwurf von fehlertoleranten sequentiellen Maschinen,
in asynchronen Systemen usw.
Wir setzten diese Arbeit in [P18] fort und
betrachteten wieder Codes über dem Alphabet
Wir studieren die
Theorem 1. Für jedes
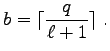
Darüberhinaus studieren wir die Klasse der
Theorem 2. Sei
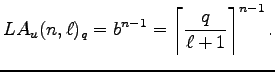
Die unkonventionellen Fehler sollen auch in dem neubeantragten Projekt fortgesetzt werden.
2. Synchronisation und Delay
In [P20] verallgemeinern wir die Resultate von Ahlswede, Balkenhol, Partner
(siehe Fortsetzungsantrag 2003). Wir geben eine Konstruktion f''ur
In ([P21]) erzielten wir einen wesentlichen Fortschritt
im Beweis der Theorem 1.
Sei
Theorem 2.
(i) Angenommen
(ii) Wenn
C Interaktive Identifikation
1. Allgemeine Theorie des Informationstransfers, gemeinsame Zufälligkeit (Common Randomness), Zufallszahlen
Alle hier dargestellten Ergebnisse wurden in Kooperation mit dem DFG-Projekt AH46/1-1,1-2, 4-1 erzielt. Ausserdem soll die Forschung in einem neubeantragten DFG-Projekt fortgeführt werden. Störungsfreie Identifikation für Quellen Wir kommen nun zu einem der Höhepunkte unserer Ergebnisse, nämlich der Entdeckung einer neuen Entropie, die wir Identifikationsentropie nennen. In [P24] haben wir fehlerfreie Quellencodierung für Identifikation eingeführt, verschiedene Gütemaße definiert und erste Ergebnisse hergeleitet. Vor der Beschreibung unseres Modells erinnern wir zunächst an den 1. Fundamentalsatz der Informationstheorie.
Shannon hat 1948 gezeigt, dass eine Quelle
wobei
Für die Quelle und den Präfixcode definieren wir nun eine
Zufallsvariable
Wir benutzen den Präfixcode für die störungsfreie Identifikation, das heißt, dass
ein Benutzer, der etwa wissen möchte, ob der Quellausgang Hiermit in Verbindung stehende Größen sind
die erwartete Anzahl von Tests für eine Person im ungünstigsten Fall,
falls der Code
Weiterhin ist
die erwartete Anzahl Tests im ungünstigsten Fall für den besten Code.
Schließlich, falls Benutzerinteresse per Zufallsvariable
die durchschnittliche Anzahl der erwarteten Tests, wenn der Code
die durchschnittliche Anzahl der erwarteten Tests für einen besten Code. Ein natürlicher Spezialfall ist die mittlere Anzahl der erwarteten Tests
Dies entspricht
Ein anderer mathematisch interessanter Spezialfall ist der Fall
So wie Shannon sich für die Abschätzung der Größe
Beispiel:
unit=0.7cm
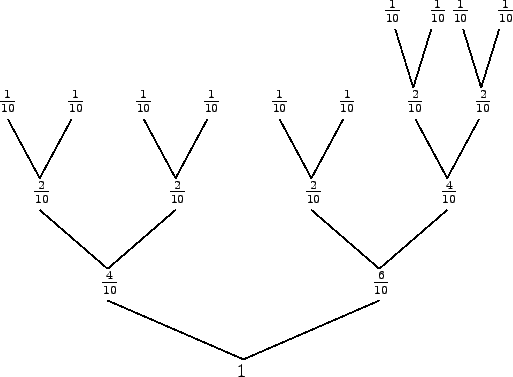
In diesem Fall gilt
Einer der 16 besten Huffman Codes sieht folgendermaßen aus:
unit=0.7cm
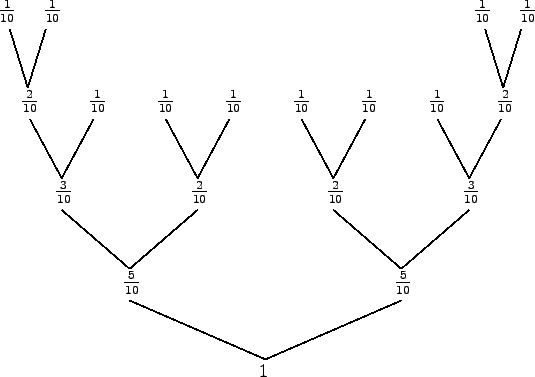
In diesem Fall gilt:
Eine Entdeckung unserer Arbeit ist die Identifikationsentropie, nämlich die Funktion
für die Quelle
Die Bedeutung von Wir haben die folgenden Hauptresultate erzielt:
Theorem 1.
Für jede Quelle
Theorem 2.
Für
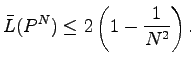
Theorem 3.
Für
Theorem 4.
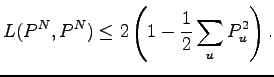
Für
Schließlich erhalten wir Korollar.
Es zeigt, dass die unterere Schranke von
Ferner wurde schon in [P6] gezeigt Theorem 5.
gilt für alle Quellen.
Die Erweiterung auf den allgemeinen
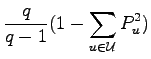
und entsprechende Verallgemeinerungen der Theoreme.
In [P25] zeigen wir, dass
Weiterhin erklären wir in [P25] die codierungstheoretische Bedeutung der beiden Faktoren in der Entropieformel.
Korrelationen von pseudo-zufälligen binären Folgen
Im folgenden wird nun über die Arbeit [P27] berichtet.
In einer Reihe von Arbeiten untersuchten Mauduit und Sárközy
(teilweise mit mehreren Koautoren, unter ihnen die Bielefelder Ahlswede und
Khachatrian) endliche pseudo-zufällige
binäre (und allgemeiner auch
Insbesondere führten sie folgende Pseudo-Zufälligkeitsmaße ein.
Das Wohlverteilungsmaß von
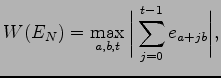
wobei das Maximum über alle
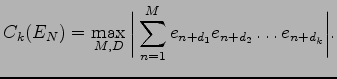
Hier erstreckt sich das Maximum über alle
Die Folge
Die verwendete Terminologie ist dadurch berechtigt, dass für
``wirklich zufällige''
In der Arbeit von C. Mauduit und A. Sárközy
``On finite pseudorandom binary sequences I. Measure of
pseudorandomness, the Legendre symbol'', Acta Arith. 1997
wird erklärt, warum das Wohlverteilungsmaß und das
Korrelationsmaß als Maße für
Pseudo-Zufälligkeit verwendet werden können.
Es ist jedoch zu erwarten, dass es Anwendungen gibt, bei denen
es genügt, nur einige statt aller pseudo-zufälligen
Maße zu kontrollieren. Eine der wichtigsten Anwendungen
der Pseudo-Zufälligkeit ist die Kryptographie.
Wenn wir z.B. eine binäre Folge
Für
Theorem 1.
Für jedes
Wir verschärfen das Theorem in dem Spezialfall, wo die Ordnung der Korrelation 2 ist.
Theorem 2.
Falls
2. Watermarking
3. Identifizierbare Eltern Eigenschaft (IPP, identifiable parent property)
D Broadcasting
II Diagnose
Die in diesem Abschnitt beschriebenen Suchprobleme sollen in einem neubeantragten Projekt weiter untersucht werden. 1. Diagnose als Suchen mit beschränkten Mengen
2. Delay
3. Sequentielle Suchmodelle mit Fehlern
Eine der wichtigsten Fragen in Multiprozessor Systemen ist die Verlässlichkeit. Die Fehler Diagnose (Identifikation der fehlerhaften Prozessoren) ist ein Bestandteil bei Erreichung der Fehler-Toleranz. Preparata/Metze/Chien (1967) führten ein graphentheoretisches Modell für selbstdiagnostizierende Systeme ein. Hierbei geht es um automatische Fehler Diagnose in Multiprozessor Systemen.
Ein System
Die Prozessoren führen Tests über ihre Nachbarn durch und senden die
Testergebnisse (``fehlerhaft'' oder ``intakt'') zu dem zentralen
Kontrolleur, dessen Aufgabe ist, die defekten Prozessoren aufgrund der
vom System erzeugten Testergebnisse zu identifizieren.
Diagnostizierbarkeit
Diagnose Probleme
In [P29] geben wir einen Diagnosealgorithmus
Die Diagnostizierfähigkeit des Algorithmus erfüllt
Die Komplexität des Algorithmus ist
Dies verbessert die Resultate von Khanna/Fuchs (1996):
Der Algorithmus ist optimal für ``schlechte'' Graphen: Es gibt Graphen
(Bäume) mit
Für den
Ist die Anzahl der Fehler
Obere Schranke:
Frühere beste untere Schranke:
Friedman (1975) führte den Begriff der Die Motivation für diese Diagnose Strategie (auch pessimistische Diagnose Strategie genannt) ist es, die Diagnostizierbarkeit eines Systems zu erhöhen (im Bezug auf die Ein-Schritt Diagnose Strategie) und gleichzeitig das Delay zu verringern (der Nachteil einer sequentiellen Diagnose Strategie) bei der Fehleridentifikation in den Großrechnersystemen.
Sei
Den Grad der Diagnostizierbarkeit eines Systems festzustellen (bei gegebenem Theorem.
Wir beschreiben auch einen einfachen Algorithmus für die
In Kooperation mit dem DFG-Projekt ``Informationstheorie und Kombinatorik'' wurden
Suchmodelle mit verschiedenen Fehlerkonzepten betrachtet.
Das Rényi-Berlekamp-Ulam Spiel ist ein klassisches Modell
zur Bestimmung der Mindestanzahl von Fragen, um eine unbekannte Zahl
in einer Menge
In der Variante, die wir in [P33] betrachten, werden Fragen mit In [P32] leiten wir eine obere und eine unterere Schranke für die Rate eines nichtbinären fehlerkorrigierenden Codes mit Rückkopplung her. Die Schranken stimmen für große Raten überein. Dies sind Verallgemeinerungen der Schranken von Berlekamp, Schalkwijk und Zigangirov im binären Fall.
Wir konnten auch zeigen, dass die Hammingschranke eine obere Schranke für
4. Monotonicity Testing and Property Testing
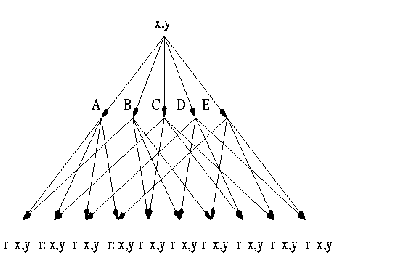
Das ``Monotonicity Testing'' ist ein Sortierproblem, das wie folgt definiert wird: Gegeben sei eine (endliche) partiell geordnete Menge In [P35] studieren wir das ``worst case'' Verhalten von ``Monotonicity Testing'' Algorithmen. Diese Untersuchungen wurden schon in den Zielen des Fortsetzungsantrags 2003 angekündigt. Zwei Modelle werden betrachtet: das Vergleichsmodell und das lineare Modell.
Ein eher überraschendes Resultat für das Vergleichsmodell ist das
Beispiel einer teilweise geordneten Menge (Poset) mit 9 Elementen und
strikt kleinerer ``monotonicity testing''
Komplexität als einige ihrer Subposets.
Der Beweis ist schwierig und nimmt 20 Seiten ein.
Ein anderes interessantes Resultat (für das Vergleichsmodell) ist das
Theorem 1.
Wenn eine Poset
Aus dem Resultat folgt, dass die Komplexität zur gleichzeitigen Feststellung,
ob in
Yao (1975) (siehe auch Aigner ``Combinatorial Search'', Kapitel 4, 1988)
fragte nach der Komplexität des simultanen Findens
des Minimums und des Maximums in einer Folge von
Eine neue unterere Schranke wird für diese Komplexität hergeleitet.
Theorem 2.
Um das Maximum und das Minimum in einer Folge von Alle Ergebnisse und der Stand der Forschung werden ausführlich in der Arbeit [P36] dargestellt.
III Vorhersagetheorie in Netzwerken
Lars Bäumer, dessen Dissertation Vorhersagetheorie in Verbindung mit Identifikation behandelte, hat nicht wie bei der Antragsstellung geplant an diesem Projekt mitgearbeitet, da er mein Forschungsprojekt am Zif als Assistent unterstützt. Er hat sich dort biologischen Fragestellungen zur Evolution von Sprachen und zur Tierkommunikation gewidmet. Vorhersagetheorie wurde deshalb in diesem Projekt nicht betrieben. Die BAT IIa-Stelle dieses Projektes hatte durchgehend Harout Aydinian inne.
IV Zwischenspeicher Managementstrategien in Netzwerken und Creating Order
Christian Wischmann wird dieses Thema in seiner Doktorarbeit behandeln. Seine ersten Ergebnisse präsentierte er auf dem Jahreskolloquium in Aachen 2006.
Weitere Literaturhinweise im Ergebnisbericht
|
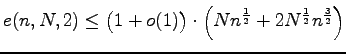
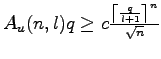
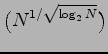
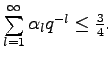
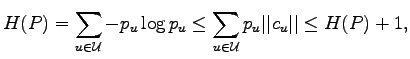
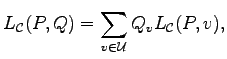
![$\displaystyle =\frac1{10}[1.6\cdot4+1.8\cdot2+2.2\cdot4]=1.880.$](img257.png)