Paralleles und verteiltes Rechnen
Inhalt
Diese Veranstaltung führt in die Grundlagen des parallelen und verteilten
Rechnens ein:
- Parallelarchitekturen,
- Parallele Programmiermodelle anhand von (iterativen)
Lineare-Gleichungssystem-Lösern...
- ...und anhand von weiteren gut parallelisierbaren Algorithmen.
Der Inhalt ist so in etwa das, was hier steht:
- Buch von Rauber-Rünger: Kapitel 2.1-2.5, 4.2, 4.5.1, (8.1, 8.3).
- Buch von Golub-Ortega: 3.2, 3.3 (nur bis "Schnelle Matrixmultiplikation"),
6.1 (nur bis "Bandmatrizen"), 7.1 (nur bis "Cholesky-Faktorisierung"), 8.1, (8.2).
- Paralleles Sortieren, so wie wir das machen habe ich das nirgends gefunden.
Die Übungen ergänzen dies komplementär mit praktischen Übungen zu
Netzwerk-Protokollen sowie Client-Server-Programmierung in python
oder perl.
Siehe auch die ekVV-Seiten zur
Vorlesung und zur Übung.
Quellen zur Vorlesung:
- T. Rauber, G. Rünger: Parallele Programmierung (pdf über Unibibliothek erhältlich)
- G. Golub, J.M. Ortega: Scientific Computing (pdfs über die Unibibliothek erhältlich)
- T. Tantau: Skript der Uni Lübeck (ein sehr gutes, allerdings machen die fast alles anders als wir. Obacht, der Link ist evtl bald nicht mehr gültig.)
Die Folien
Die handschriftlichen Folien, bzw Tafelanschriebe.
- (17.10.) Kap. 1: Parallele Architekturen:
n-bit-Rechner, Vektorrechner
- (24.10.) Kap. 1: Parallele
Architekturen: Pipelining, SISD, SIMD, MIMD
- (31.10.) Kap. 2: Netzwerktopologie:
Graphen; die Kandidaten.
- (7.11.) Kap. 2: Die Sieger;
Einbettungen;
zur Preisfrage: Einbettung
vollständiger Binärbäume in Gittergraphen.
- (21.11.) Kap. 3: Parallele Rechnermodelle:
Übersicht;
RAM einfach;
RAM erweitert - PRAM;
CRCW - CREW - EREW.
- (28.11.) Kap. 4: Parallelisierbarkeit:
axpy - summieren;
A·v - erfüllende Belegungen;
Amdahls Gesetz.
- (5.12.) Kap. 5: Erinnerung an
Lineare Algebra, Kap. 6: Lineare Algebra-Operationen parallel:
axpy - ⟨v, w⟩,
A·x .
(Entschuldigen Sie die Qualität, ich habe die Fotos verbockt)
- (12.12.) Kap. 6: Lineare Algebra-Operationen parallel:
A·B Schleifen schachteln,
A·B Speicherzugriff.
- (19.12.) Kap. 7: Sortieren auf Parallelrechnern:
Mergesort klassisch,
Mergesort parallel: Idee,
Mergesort parallel: Algorithmus und Laufzeit.
(Sorry, die ai heißen im Beweis nach Schritt 2 plötzlich ki.)
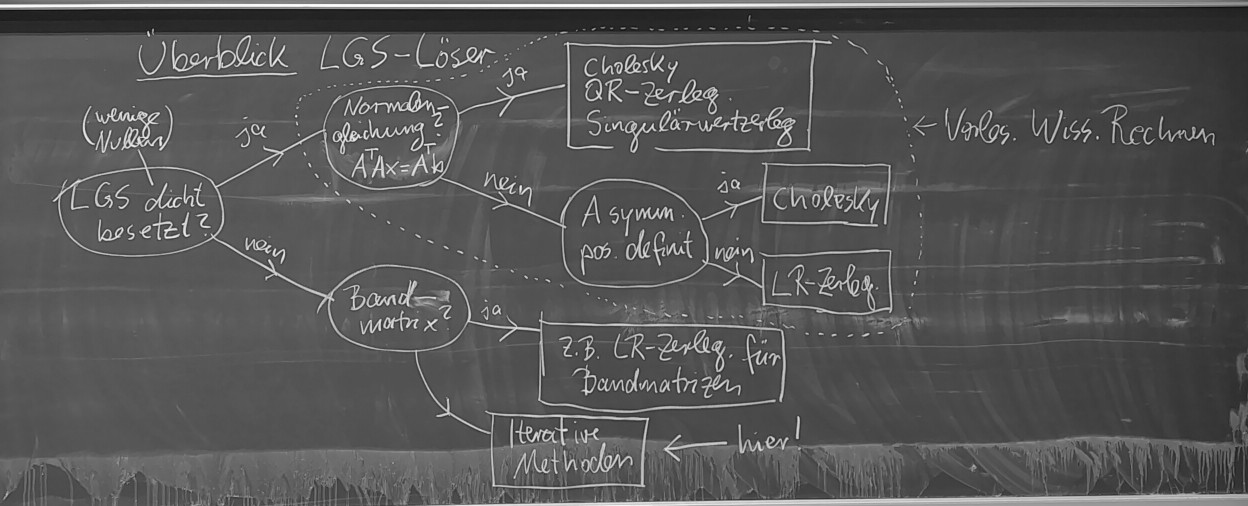
- (9.1.) Kap. 8: Lineare Gleichungssysteme, direkte Verfahren:
LR-Zerlegung,
Vorwärtssubstitution,
Rückwärtssubstitution naiv,
Rückwärtssubstitution schlau,
Überblick LGS-Löser.
- (23.1.) Kap. 9: Lineare Gleichungssysteme, iterative Verfahren: Jacobi-V:
Formel,
Pseudocode,
zur Laufzeit.
- (30.1.) Kap. 9: Lineare Gleichungssysteme, iterative Verfahren: Konvergenz Jacobi-Verf.
Teil 1,
Teil 2, sowie
Gauß-Seidel und SOR.
Organisatorisches
- Vorlesung: Fr 12-14 in H16. (letzte Vorlesung am 30.1.)
- Übungen: Als Block nach der Vorlesungszeit, siehe
ekVV.
Zuletzt geändert am 30.1.2026
Dirk Frettlöh
{kind=link}
{kind=link}
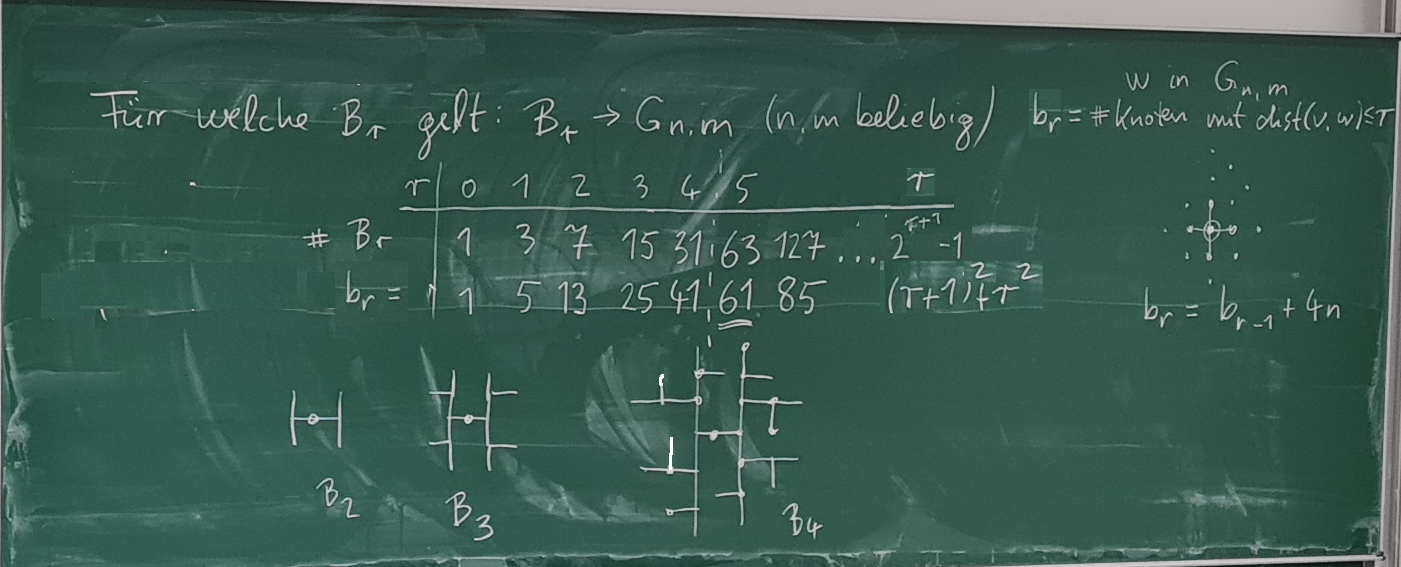{kind=link}
{kind=link}
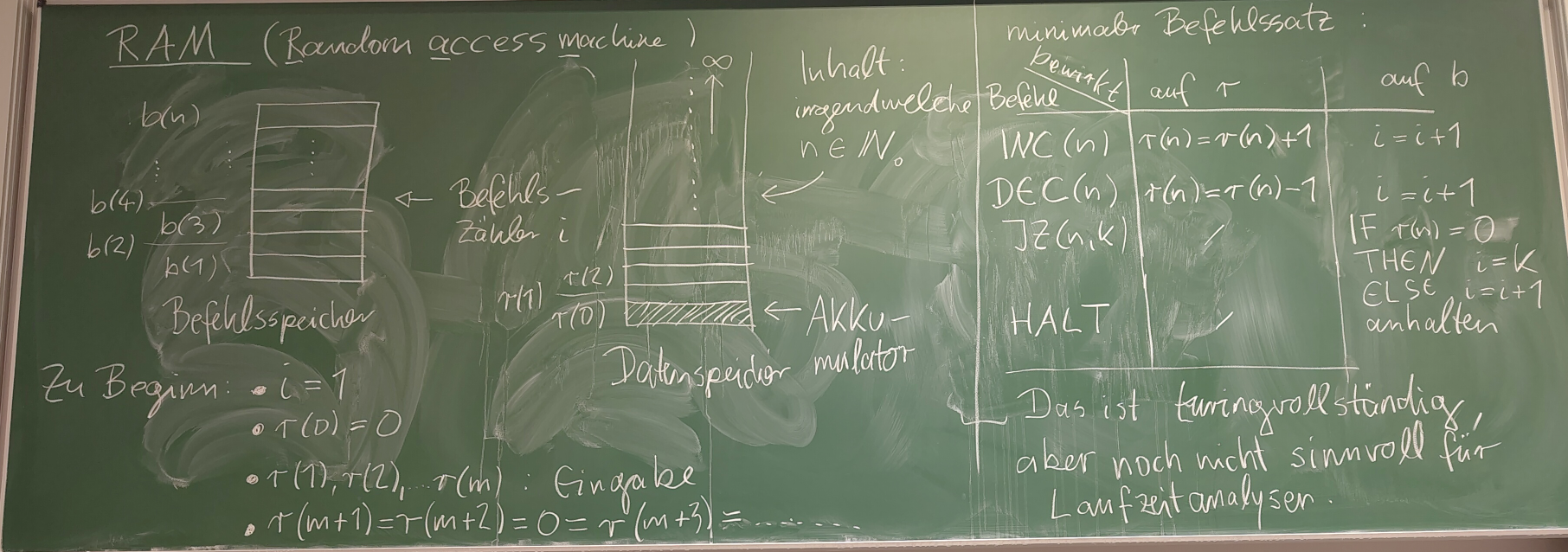{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
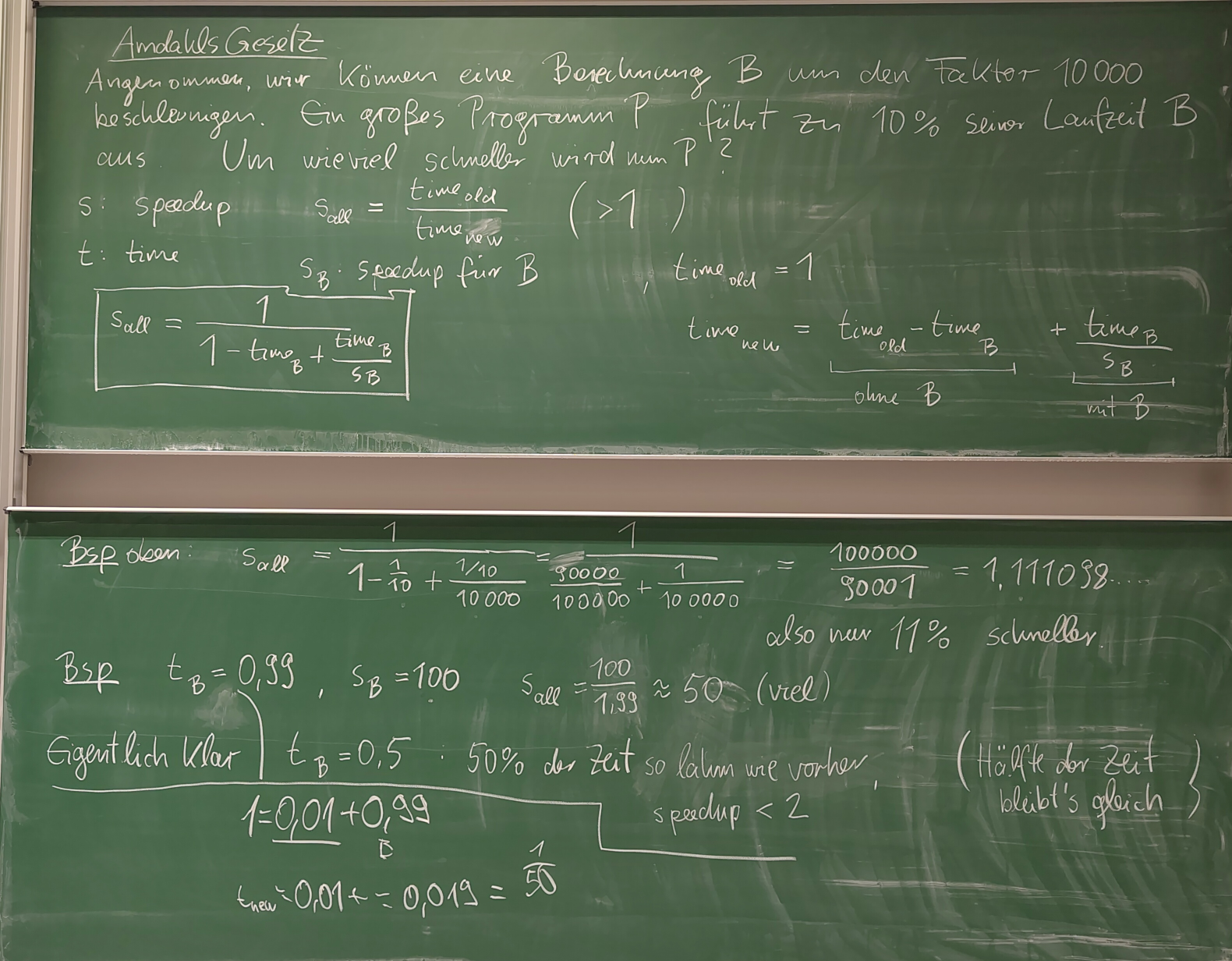{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
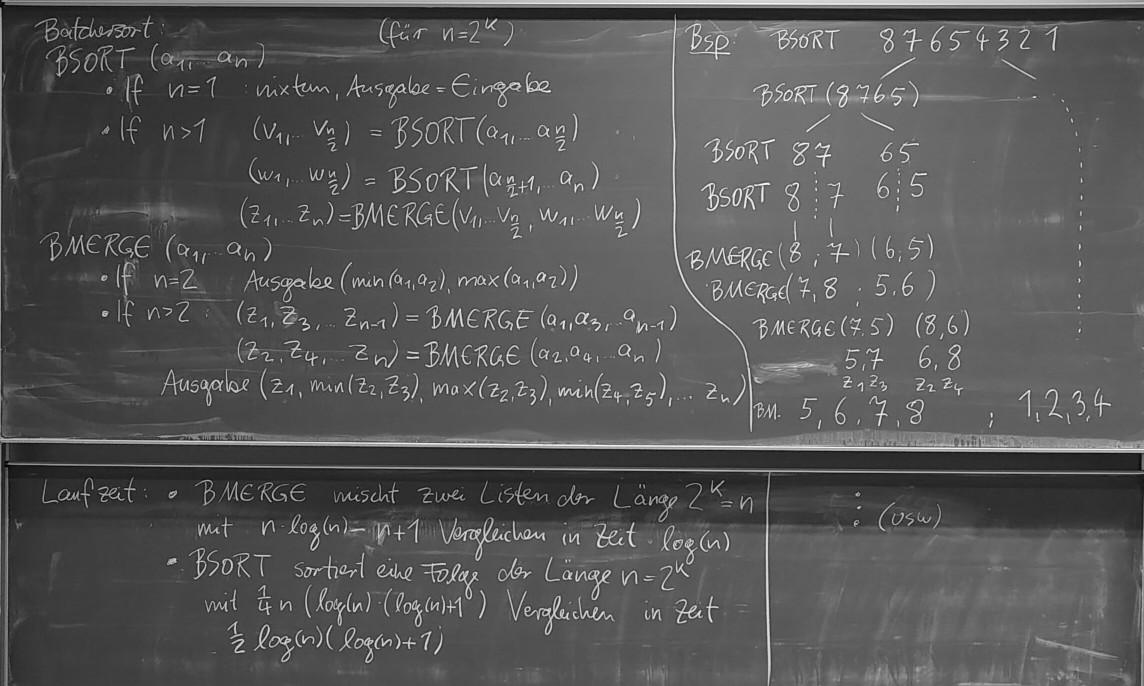{kind=link}
{kind=link}
{kind=link}
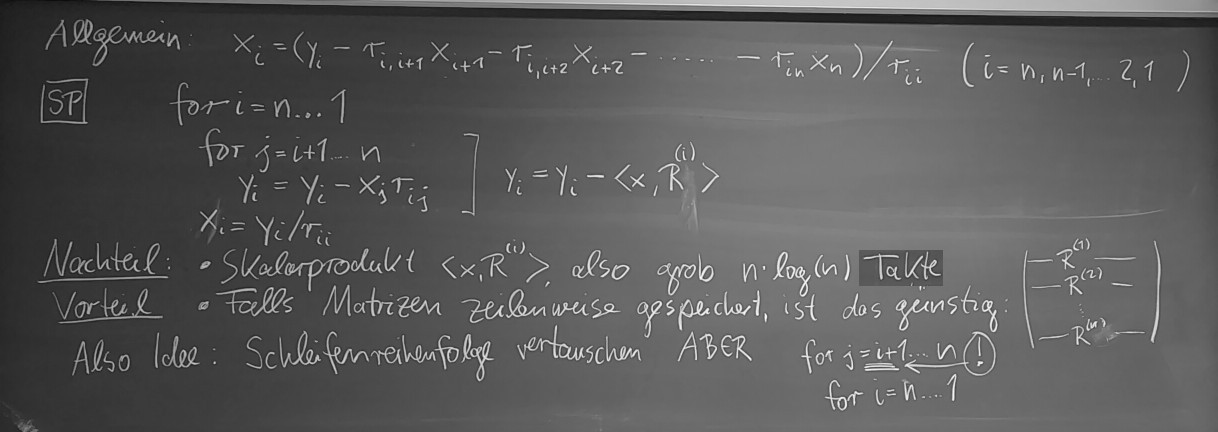{kind=link}
{kind=link}
{kind=link}
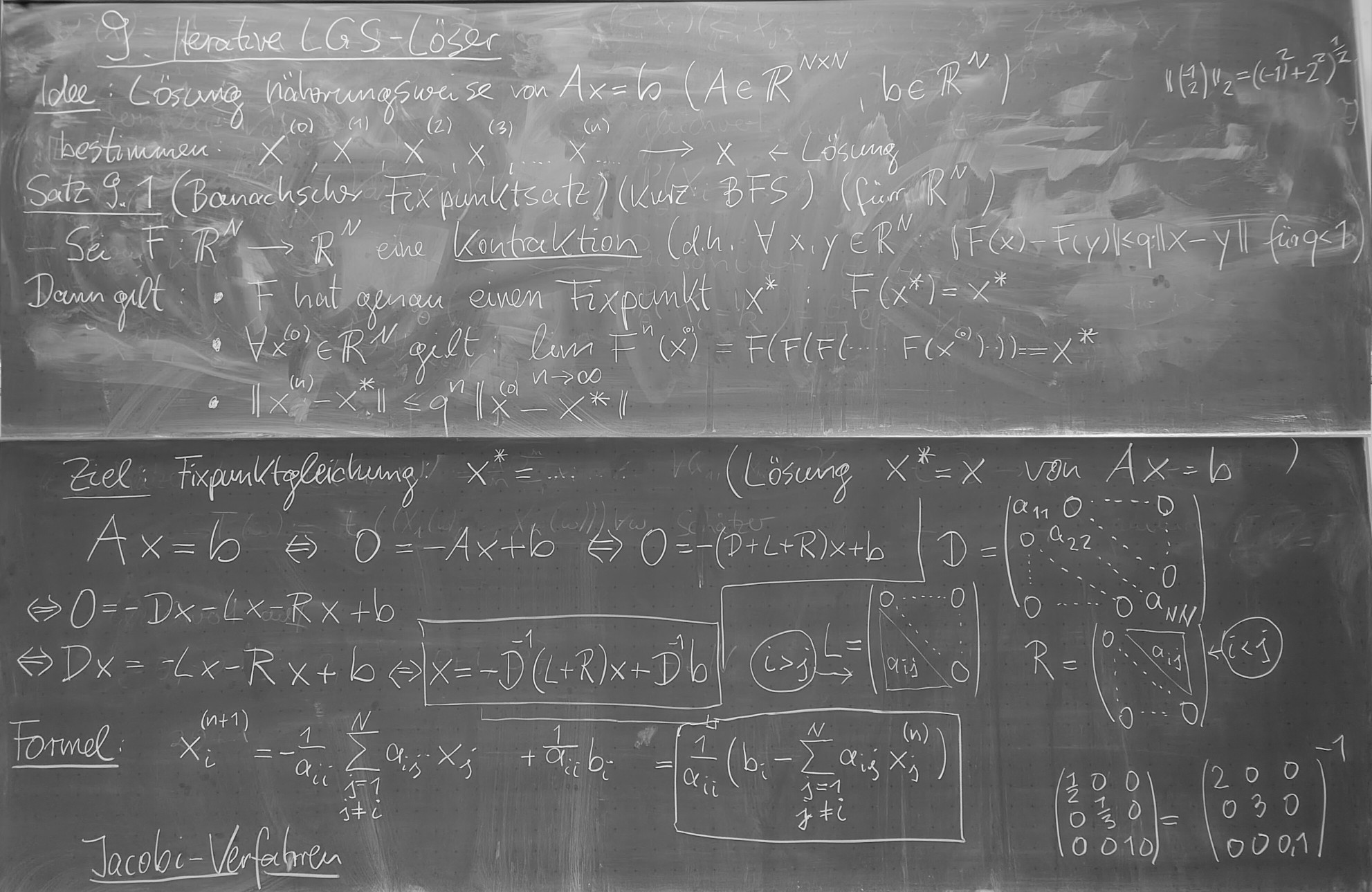{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}